【データ分析】pandasの基本を解説!Series型とデータフレームの操作

こんにちは、爽です。皆さん、いかがお過ごしでしょうか?
今回はデータ分析でよく用いられるライブラリであるpandasについて確認します。
pandasもnumpyと同様にデータ分析、統計、機械学習、及びディープラーニングなどで用いられる頻度の高い重要なライプラリとなります。この記事では基本を紹介しています。
なお、numpyとmatplotlibの基本については以下の記事でまとめていますのでこちらも合わせてご参考ください。
・numpy
・matplotlib

今回はデータ分析でよく用いられるライブラリであるnumpyについて確認します。
numpyはデータ分析、統計、機械学習、及びディープラーニングなどで用いられる頻度の高い重要なライプラリとなります。この記事では基本を紹介しています。
■この記事の対象読者
・pandasの基本を確認したい方
・データ分析に興味のある方
なお、私はPythonをAnacondaをインストールしてJupyterで実行しています。MacのAnacondaのインストール方法とJupyterの使い方は下記記事にまとめているので良かったらご参考ください。
また、Anacondaをインストールするとインストールの時点でpandasも同梱されるので便利です。

それではどうぞ!
目次
pandasとは
pandasとは主に表データを扱うためのライブラリで、numpyと同様にデータ分析、統計、機械学習、及びディープラーニングなどの科学計算の場面でよく用いられるライブラリです。読み方は「パンダス」です。
上記で記載した科学計算をする前に、データの読み込み・及び前処理が必要になってくるのですが、pandasを使えばそのような操作を簡単に行うことができます。
なお、pandasはnumpyをベースに作られているため、numpyでできることはpandasでもできることが多いです。
Series型
Series型とはインデックス付きのnumpyの配列のようなデータです。
Series型の生成
Series型はSeries()メソッドを使って生成できます。
import numpy as np
import pandas as pd
data = pd.Series([1, 2, 3, 4, 5])
data
# 0 1
# 1 2
# 2 3
# 3 4
# 4 5
# dtype: int64Series型の要素へのアクセス
Series型にはnumpyと全く同じ要領で変数名[インデックス]の形式でアクセス可能です。
data[4]
# 5なお、リストなどと同じように存在しないインデックスを指定するとエラーになります。
インデックスの指定
Series型を生成する際に、indexにパラメータを指定するとインデックスを任意のものに指定できます。
list = [1, 2, 3, 4, 5]
index = ['a', 'b', 'c', 'd', 'e']
data = pd.Series(list, index=index)
data
# a 1
# b 2
# c 3
# d 4
# e 5
# dtype: int64インデックスの確認と値の確認
indexプロパティを使うことでインデックスの確認、valuesプロパティを使うことで値の確認ができます。
list = [1, 2, 3, 4, 5]
index = ['a', 'b', 'c', 'd', 'e']
data = pd.Series(list, index=index)
#インデックスの確認
print(data.index)
# Index(['a', 'b', 'c', 'd', 'e'], dtype='object')
#値の確認
print(data.values)
# [1 2 3 4 5]データフレームの基本
データフレームとはインデックス付きの表データのことです。なお、列はSeries型になっています。
なお、利用頻度に関しては、上記で記載したSeries型よりもデータフレーム型の方が圧倒的に多いです。
データフレームの生成
データフレームはDataFrame()メソッドを使って、辞書型の形式でキーに列名、バリューに値を指定することで生成できます。
なお、データフレームはdfという変数に格納されることが多いです。
import numpy as np
import pandas as pd
id = [1, 2, 3, 4, 5,]
name = ['Taro', 'Jiro', 'Saburo', 'Shiro', 'Goro']
age = [30, 27, 24, 21, 18]
address = ['Tokyo', 'Tokyo', 'Osaka', 'Osaka', 'Tokyo',]
#辞書型でデータフレームを生成
df = pd.DataFrame(
{
'id':id,
'name':name,
'age':age,
'address':address
}
)
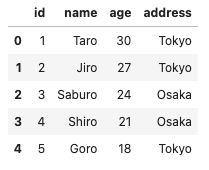
df
# id name age address
# 0 1 Taro 30 Tokyo
# 1 2 Jiro 27 Tokyo
# 2 3 Saburo 24 Osaka
# 3 4 Shiro 21 Osaka
# 4 5 Goro 18 Tokyoなお、Jupyterでデータフレームを表示するとこのように以下のように表形式で表示されます。
列へのアクセス
データフレームの列にアクセスする方法は2種類の形式があります。
1つは変数名['列名’]の形式、2つ目は変数名.列名の形式です。どちらでも同じ結果になりますが、他の人のソースを見ると前者の形式で記述されることが多い印象です。
#列参照方法①
print(df['age'])
#列参照方法②
print(df.age)
# 0 30
# 1 27
# 2 24
# 3 21
# 4 18
# Name: age, dtype: int64また、一度に複数の列にアクセスすることも可能です。形式は変数名[['列名1’, '列名2’…]]です。
#複数の列にアクセス
df[['name', 'age']]
# name age
# 0 Taro 30
# 1 Jiro 27
# 2 Saburo 24
# 3 Shiro 21
# 4 Goro 18
データフレームの全体像の確認
実際の業務においては、対象のデータの全体像を把握してから前処理→分析と進んでいきます。
ここでは実際の業務の最初のステップであるデータの全体像を把握するための基本的なプロパティとメソッドを紹介します。
#shapeでデータフレームの行数と列数を確認
print(df.shape)
#最初の数字が行数、2番目の数字が列数
# (5, 4)
#head()メソッドで最初の数行のデータを表示する
#引数に何も数字を指定しない場合は5行表示
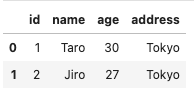
df.head()
#head()メソッドの引数に数字を指定すればその行数文表示
df.head(2)
#tail()メソッドで最後の数行のデータを表示する
#こちらも引数に何も数字を指定しない場合は5行表示
#dtypesでデータフレームが保持する列の型を確認
print(df.dtypes)
# id int64
# name object
# age int64
# address object
# dtype: object
また、describe()メソッドを使えばそのデータフレームの統計量を表示することが可能です。個人的にこのメソッドはデータの全体像を把握するためにかなり適したメソッドだと思っています。
#統計量を確認
df.describe()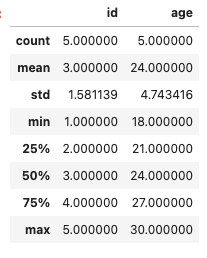
データフレームの条件の指定と並び替え
データフレームではSQLと同様に簡単に条件の指定と並び替えができます。
条件の指定
条件の指定は変数名[変数名[列名] 抽出条件]の形式で可能です。
例えば年齢が25歳以上のレコードを抽出する為には以下のように記述します。
#条件に合致するデータの抽出
df[df['age'] > 25]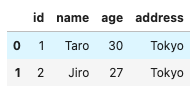
もちろん、数字以外にも文字列での条件の指定も可能です。
#文字列での検索も可能
df[df['address'] == 'Tokyo']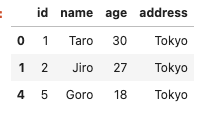
また、複数の条件を指定した場合は、isin()メソッドを利用します。
#複数条件を指定
df[df['age'].isin([30, 27])]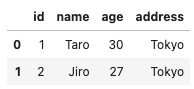
並び替え
条件の並び替えはsort_values()メソッドを使います。
なお、デフォルトでは昇順(値が小さい順)で並び替えがされます。
#年齢の昇順でデータを並び替え
df.sort_values(by='age')
降順(値が大きい順)で並び替えたい場合は、ascendingのパラメータにFalseを指定します。
#年齢の降順でデータを並び替え
df.sort_values(by='age', ascending=False)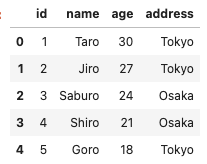
データフレームの集計
numpyと同じようにpandasでもデータフレームに対して集計をかけることができます。
ここでは基本的な集計関数を記述しておきます。
#value_counts()関数で列の値の数を数える
print(df['address'].value_counts())
# Tokyo 3
# Osaka 2
# Name: address, dtype: int64
#sum()関数で列を合計
print(df['age'].sum())
# 120
#mean()関数で列を平均
print(df['age'].mean())
# 24.0
#max()で列の最大値を取得
print(df['age'].max())
# 30
#min()で列の最小値を取得
print(df['age'].min())
# 18
#median()関数で列の中央値を取得
print(df['age'].median())
# 24.0
#std()関数で列の標準偏差を取得
print(df['age'].std())
# 4.743416490252569データフレームの集約
データフレームで集約も可能です。メソッドはSQLと同じようにgroupby()メソッドを使用し、基本的には前のセクションで紹介した集約関数と組み合わせることが多いです。
#addressで集約してグループごとに各カラムの平均を求める
df.groupby('address').mean()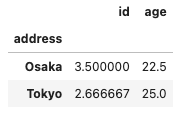
なお、上記の中でidの列は集約する意味がありませんので不要ですね。
従って、特定の列のみを集約して表示することも可能です。下記の例では住所を集約、住所ごとに年齢の平均をとっています。
#年齢をグループ化
df[['age', 'address']].groupby('address').mean()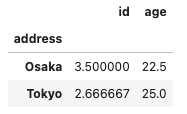
また、SQLと同様に複数の列での集約と集計も可能です。集約はpandasの中でも非常に重要な要素なので詳細はまた違う記事でまとめたいと思います。
データフレームのスライス
リスト同様にデータフレームではスライスでデータを取り出すことができます。
特にilocは機械学習でデータを訓練データとテストデータに分けるときに頻繁に使われる為、非常に重要です。
スライス
スライスはリストと同じ要領で変数名[開始行のインデックス,終了行の直前のインデックス]の形式で、このように指定することで行単位でレコードを取り出すことができます。
例えば1行目から3行目を取り出したい場合は変数名[0:3]のように指定します。Pythonのインデックスは0から始まるので間違えないようにしましょう。
import numpy as np
import pandas as pd
#データフレーム生成
df = pd.DataFrame(np.random.randn(6,4), columns=['A', 'B', 'C', 'D'])
#1行目から3行目を取り出す
df[0:3]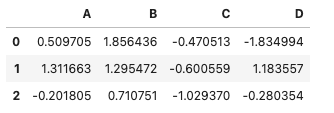
なお、全ての行を取り出す為には開始と終了のインデックスに数字を何も指定しないことで取り出せます。
#全行取り出す
df[:]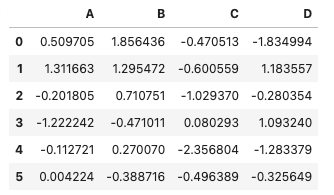
locとiloc
スライスと同様に、locとilocでも同じようにデータを抽出することができます。
locとilocを使えば取り出す行だけではなく、取り出す列の指定ができる為、より細やかなデータ抽出が可能です。書式はlocもilocも変数名.loc[行の指定,列の指定]の形式となります。両者の違いは下記です。
・loc:取り出したい行と列をそれぞれのインデックス名、及び列名で指定する必要がある。
・iloc:取り出したい行と列をそれぞれの番号で指定する必要がある
例えば下記のようにインデックス名と列名をつけたデータフレームを作成します。
import numpy as np
import pandas as pd
#データフレーム生成
df = pd.DataFrame(np.random.randn(6,4), index=pd.date_range('20220101', periods=6), columns=['A', 'B', 'C', 'D'])
df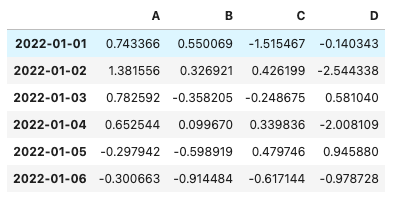
locは下記のようにインデックス名と列名を指定してデータを取り出す必要があります。
例えば下記の例は先頭2行と左の2行を取り出す例です。
#取り出したい行と列のインデックス名と列名を指定
df.loc['20220101':'20220102', ['A', 'B']]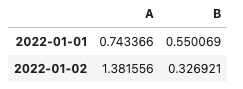
一方でilocは下記のようにインデックス番号と列番号を指定してデータを取り出せます。
下記の例は上記のilocの例と同様に先頭2行と左の2行を取り出す例です。
#取り出したい行と列の番号を指定
df.iloc[0:2, 0:2]
個人的にはilocの方がインデックス名と列名を意識せずに使えるので使いやすいかと思ってます。
なお、特に機械学習では最後の列を目的変数、それ以前の列を説明変数とすることがありますが、最後の列とそれ以外の列を取り出す方法はそれぞれ下記です。
#最後の列以前を取り出す
x = df.iloc[:, :-1]
x
#最後の列のみを取り出す
y = df.iloc[:, -1:]
y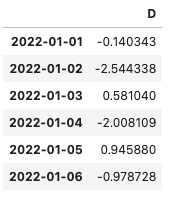
データフレームの列と行の追加
既に生成しているデータフレームに対して、列と行を追加することも可能です。
列の追加
列の追加方法としてはリストを追加する方法とSeries型を追加する方法の2種類があります。
まず、リストを追加する場合は、変数名[追加したい列名] = リストの形式で追加できます。
import numpy as np
import pandas as pd
#データフレーム生成
df = pd.DataFrame(np.random.randn(6,4), index=pd.date_range('20220101', periods=6), columns=['A', 'B', 'C', 'D'])
#新しいE列にリストを追加
df['E'] = [1, 2, 3, 4, 5, 6]
df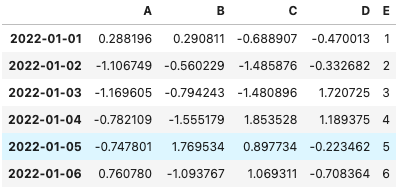
Series型もリストの時と同じ要領で変数名[追加したい列名] = Series型の形式で追加できます。
#インデックス名をデータフレームと揃える
s = pd.Series([1, 2, 3, 4, 5, 6], index=pd.date_range('20220101', periods=6))
#新しいE列にSeries型を追加
df['E'] = s
dfただし、Series型で追加する場合は追加するデータフレームにインデックス名がついている場合、インデックス名を揃える必要があります。もしインデックス名を揃えずに追加するとNanで追加されてしまうので注意しましょう。
#インデックス名を付与しない
s = pd.Series([1, 2, 3, 4, 5, 6])
#新しいE列にSeries型を追加すると追加した値が全てNanになる
df['E'] = s
df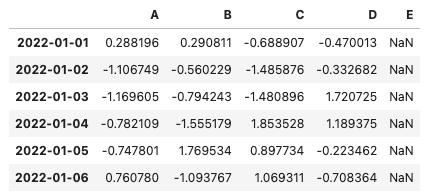
行の追加
行の追加に関しては、concat()メソッドを使用します。
なお、行を追加する為には、append()メソッドも使えますが、append()メソッドを利用するとJupyterでは下記のワーニングが出力されます。
/var/folders/n5/5gbwrl3x1rj524_v2f87mgg40000gn/T/ipykernel_969/958814039.py:1: FutureWarning: The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
df.append(df[0:2])
このワーニングはappend()メソッドはいずれ使えなくなるので気をつけてくださいねという意味です。私の端末のPythonのバージョンは3.9.7でまだ使えていますが、いずれappend()メソッドは使えなくなってしまうため、行を追加したい場合はconcat()メソッドを使うようにした方が良いです。従ってこちらの記事ではconcat()メソッドのみ使い方を紹介します。
concat()メソッドでの行の追加のサンプルは下記コードです。
import numpy as np
import pandas as pd
#データフレーム生成
df2 = pd.DataFrame(np.random.randn(6,4), index=pd.date_range('20220101', periods=6), columns=['A', 'B', 'C', 'D'])
#concat()メソッドで既存のデータフレームに行を追加
pd.concat([df2, df2])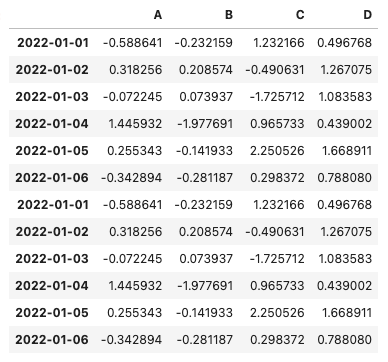
なお、データフレーム同士の列構造が一致していない場合、列が不足している側のデータフレームの列にはNanが入ります。例えば、下記の例ではdf4にはD列が存在しない為、concat()で追加後はNanが入ります。
import numpy as np
import pandas as pd
#データフレーム生成
#4列のデータフレーム
df3 = pd.DataFrame(np.random.randn(6,4), index=pd.date_range('20220101', periods=6), columns=['A', 'B', 'C', 'D'])
#3列のデータフレーム
df4 = pd.DataFrame(np.random.randn(6,3), index=pd.date_range('20220101', periods=6), columns=['A', 'B', 'C'])
#列構造が異なるデータフレームを追加
pd.concat([df3, df4])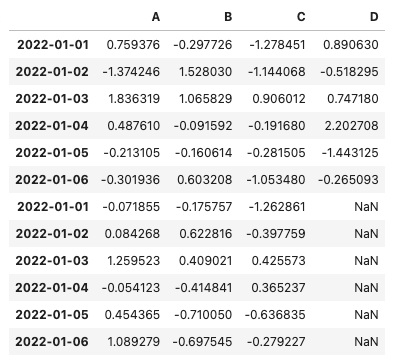
参考資料
この記事はUdemyの現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイルという講座と【データサイエンス×ビジネスコミュニケーション】現役データサイエンティストが教える「伝えて動かすデータ分析」という2つの講座を参考にさせていただき、作成しました。
現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
当講座はPythonの基礎から応用まで幅広く学べる講座なのでおすすめです。
この講座の講師はとにかくPythonについての知識が豊富ですし、話も適度な速さで聞き取りやすいです。さすがのシリコンバレーです。
また、最後の方に機械学習で使うライブラリについても解説があるので、データサイエンス・AIについても多少知ることができます。
当講座のおすすめポイントを以下にまとめておきます。
シリコンバレーで働いているということもあり、講師のPythonの知識が豊富
話も適度な速さで聞き取りやすい
コードの意味だけでなく、それをどう応用するかまで解説してくれる
【データサイエンス×ビジネスコミュニケーション】現役データサイエンティストが教える「伝えて動かすデータ分析」
当講座のおすすめポイントを以下にまとめておきます。
Pythonを知らなくても講座の中で学ぶことが可能なので初学者でもOK
データサイエンスの手法だけでなく、それをどのようにビジネスに活かすかまで学べる
この講座の最大の特徴は、データサイエンスを実務でどのように活かすかまで言及されている点です。
他の講座だとデー分析の手法や機械学習の実装方法だけ伝えるものもあるのですが、この講座はデータサイエンスの習得を目的とせず、その先を見据えた講義になっているので、実務での使用イメージが湧きやすいです。
なお、Udemyについては以下の記事でまとめていますのでご参考ください。

まとめ
ということで、今回はデータ分析でよく用いられるライブラリであるpandasについて解説しました。
この記事では基本しか紹介できていませんが、pandasもnumpyと同様にデータ分析の現場ではほぼ必須となるライブラリなので、使いながら使い方を覚えていきましょう!
個人的にはpandasはnumpyよりも使用頻度が高いと思うので少し深掘りした記事もいずれ書く予定です。
では、今回はここまでとさせていただきます。