【データ分析】scikit-learnを使って住宅価格データを分析・機械学習してみる

こんにちは、爽です。皆さん、いかがお過ごしでしょうか?
今回は以前と同様、データ分析でよく用いられるライブラリであるscikit-learnについて確認します。
以前の記事でscikit-learnのあやめデータを触ってみましたが、今回もscikit-learnを使って住宅価格データを分析・機械学習してみようと思います。あやめデータを使って分析した際の記事は以下です。
・【データ分析】scikit-learnを使ってあやめデータを分析・機械学習してみる

なお、今回の記事はnumpy,pandas,matplotlibを理解できている前提で記載しています。
もし上記ライブラリの基本を知りたい方は以下の記事にまとめているので合わせてご参考ください。
・numpy
・pandas

・matplotlib

■この記事の対象読者
・データ分析に興味のある方
なお、私はPythonをAnacondaをインストールしてJupyterで実行しています。MacのAnacondaのインストール方法とJupyterの使い方は下記記事にまとめているので良かったらご参考ください。

それではどうぞ!
住宅データの基礎分析
では早速、住宅価格データの基礎分析をしてみたいと思います。住宅価格データはscikit-learnに同梱されているボストンの住宅価格のデータのことで、データ分析する際の入門のデータセットとして頻繁に用いられます。こちらもあやめデータと同様にscikit-learnさえ使える環境であれば、データを自分で準備する必要はありません。
ということであやめデータの時と同様、いろいろ分析をやっていきたいと思います。
まず分析の前に scikit-learnをインストールしていない人はpip installで入れてください。こんな感じに表示されればインストール完了です。
pip install sklearn
# Collecting sklearn
# Using cached sklearn-0.0-py2.py3-none-any.whl
# Requirement already satisfied: scikit-learn in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from sklearn) (1.0.2)
# Requirement already satisfied: numpy>=1.14.6 in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from scikit-learn->sklearn) (1.21.2)
# Requirement already satisfied: scipy>=1.1.0 in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from scikit-learn->sklearn) (1.7.3)
# Requirement already satisfied: joblib>=0.11 in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from scikit-learn->sklearn) (1.1.0)
# Requirement already satisfied: threadpoolctl>=2.0.0 in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from scikit-learn->sklearn) (2.2.0)
# Installing collected packages: sklearn
# Successfully installed sklearn-0.0
# Note: you may need to restart the kernel to use updated packages.
データ読み込み
まずはデータを読み込みます。
from sklearn.datasets import load_boston
import pandas as pd
boston = load_boston()
#データフレームに変換
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.target
df
各列の説明は以下となります。
- CRIM: 町別の「犯罪率」
- ZN: 25,000平方フィートを超える区画に分類される住宅地の割合=「広い家の割合」
- INDUS: 町別の「非小売業の割合」
- CHAS: チャールズ川のダミー変数(区画が川に接している場合は1、そうでない場合は0)=「川の隣か」
- NOX: 「NOx濃度(0.1ppm単位)」=一酸化窒素濃度(parts per 10 million単位)。この項目を目的変数とする場合もある
- RM: 1戸当たりの「平均部屋数」
- AGE: 1940年より前に建てられた持ち家の割合=「古い家の割合」
- DIS: 5つあるボストン雇用センターまでの加重距離=「主要施設への距離」
- RAD: 「主要高速道路へのアクセス性」の指数
- TAX: 10,000ドル当たりの「固定資産税率」
- PTRATIO: 町別の「生徒と先生の比率」
- B: 「1000(Bk – 0.63)」の二乗値。Bk=「町ごとの黒人の割合」を指す
- LSTAT: 「低所得者人口の割合」
- MEDV:「住宅価格」(1000ドル単位)の中央値。通常はこの数値が目的変数として使われる
※参考外部リンク:https://atmarkit.itmedia.co.jp/ait/articles/2006/24/news033.html
今回はこのデータでMEDV「住宅価格」以外の様々なデータを用いてデータ分析を行い、最終的にはMEDV「住宅価格」を予測するためのモデル構築をしていきます。
データ確認
describe()でデータの外観を調べます。
df.describe()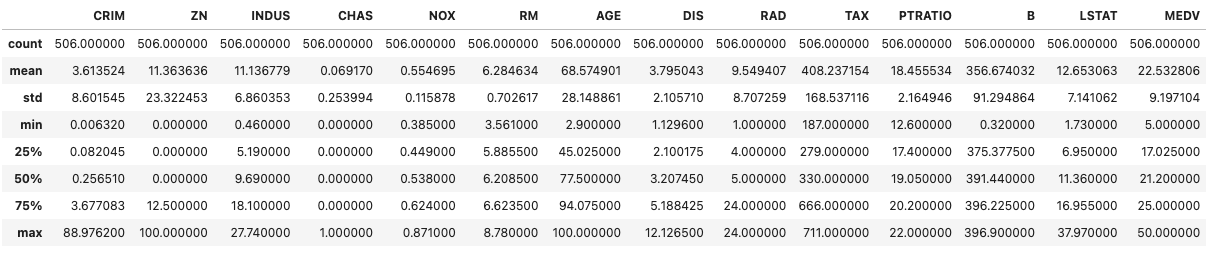
この結果を見ると全ての列は数値データであり、欠損値がない綺麗なデータであることが分かります。
ただし、今回はあやめデータと違ってデータ量が多く、外れ値の有無やデータに異常があるかどうかの判断はぱっと見では難しいので、もう少しデータを詳しく見ていく必要があります。
また、機械学習においては説明変数があればあるほど予測精度が上がるわけではなく、モデル予測において不必要なデータを入れて学習させてしまうとむしろモデルの精度が下がってしまうこともあります。
従って、今回は住宅価格に影響がありそうなデータに絞ってモデルを構築してみます。
なお、今回のようにデータ量が多い場合は全てのデータを確認すると時間がかかる為、ある程度確認するデータを絞って調査するのも1つの手です。
今回の例で言うと、住宅価格に影響しそうなデータは何かと考えた時に、住宅が新しいほど住宅価格は上がりそうなのでAGEが影響ありそうだなとか、治安が良い街の方が住宅価格が上がりそうなのでCRIMが使えそう、とかですね。従って、今回は住宅価格に関係がありそうなデータををいくつかピックアップしてデータを調べてみます。
#seabornのインストール
#pip install seaborn
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#住宅価格に関係がありそうなデータをピックアップ
cols = ['CRIM', 'ZN', 'CHAS', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'LSTAT', 'MEDV']
#pairplotで関係性を可視化する
sns.pairplot(df[cols])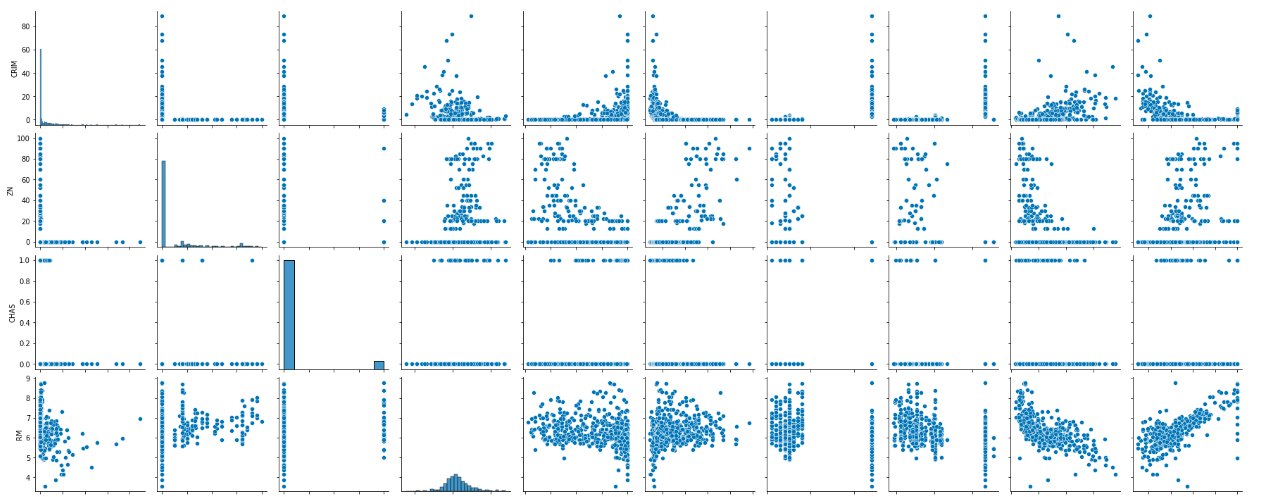
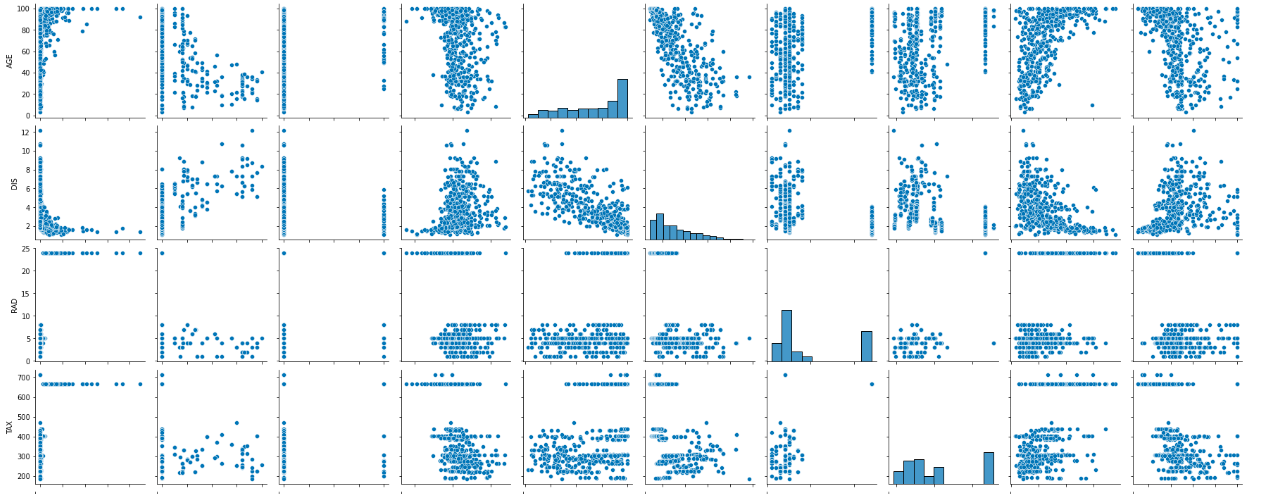
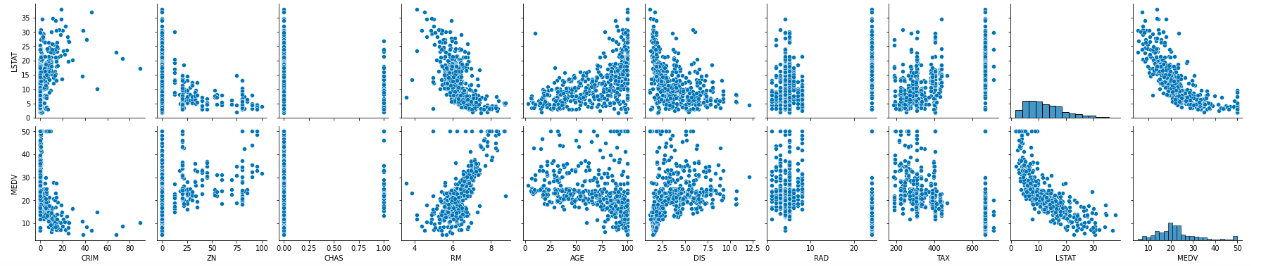
seabornのpairplot()メソッドを使うと選択したデータ同士で散布図を描くことができ、直感的に選択したデータ同士の相関関係を把握できるため、非常に便利です。
上記のpairplot()の結果の1番下の行を見るとMEDVと各列の関係性を見ることが出来ますが、特にRMはMEDVと比例関係の傾向を示しており、CRIMとLSTATはMEDVと反比例の関係を示しています。
また、AGEとDISは関係がありそうか目視では判断をつけづらいなので相関係数を出してみます。
print(df['AGE'].corr(df['MEDV']))
print(df['DIS'].corr(df['MEDV']))
# -0.37695456500459606
# 0.24992873408590388結果としてどちらもそれほど関係がなさそうでした。相関係数は-1〜1で表され、-1に近ければ近いほど負の相関性があり、1に近ければ近いほど正の相関があります。どれくらいの数字からが関係が強いと言えるのかは難しいところですが、相関係数が-0.5以下、もしくは0.5以上であれば関係があると言えるかと思うので考慮しても良いと考えます。
念の為、他に関係がありそうなデータがないか調べたところ、PTRATIOは-0.5以上の負の相関があることを確認できました。
print(df['PTRATIO'].corr(df['MEDV']))
# -0.5077866855375615従って、今回はRM、LSTAT、PTRATIOの3つのデータを使って住宅価格を予測してみたいと思います。なお、CRIMはLSTATと似たような意味合いのデータですので今回は使わずにおこうと思います。また、データを再度確認し、気になるような外れ値はみられなさそうなので、今回はデータ補正は行わずにこのままモデル構築をしていきます。
print(df['PTRATIO'].corr(df['MEDV']))
# -0.5077866855375615
cols = ['RM', 'PTRATIO', 'LSTAT', 'MEDV']
sns.pairplot(df[cols])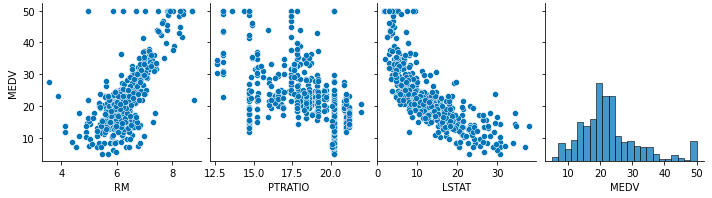
住宅価格データで機械学習
では、前の章でピックアップしたデータを使ってモデルを構築していきます。
今回のデータでやりたいことは、ある説明変数を入力したときにMEDVがいくらになるかを予測することです。従って、今回は線形回帰モデルのアルゴリズムを使用した教師あり学習の回帰分析をやってみます。
訓練データとテストデータの準備
まずは訓練データとテストデータの準備です。
cols = ['RM', 'PTRATIO', 'LSTAT']
#説明変数
X = df[cols].values
#目的変数
y = df['MEDV'].values
#訓練データとテストデータの準備
from sklearn.model_selection import train_test_split
#既存のデータをトレーニングデータとテストデータに分割
# パラメータ:test_sizeでテストに使うデータの割合を指定可能
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
# データの確認
print("X: ", X.shape)
print("X_train: %s / X_test: %s / y_train: %s / y_test: %s" % (X_train.shape, X_test.shape, y_train.shape, y_test.shape))モデル構築
上記で訓練データを用意できたため、このデータを用いてモデルを構築していきます。
#linear_modelをimport
import sklearn.linear_model
#予測モデルの初期化
classifier = sklearn.linear_model.LinearRegression()
#Xを入力した時にyを出力するように学習
classifier.fit(X_train, y_train)上記で作成したモデルの精度を確認してみます。
今回は「平均二乗誤差(Mean Squared Error: MSE)」を用いて予測モデルの評価を行います。これはモデルの誤差が大きいほど値が大きくなり、逆に誤差が小さいほど値も小さくなる指標です。数式だと下記のように表せます。

#評価用の関数読み込み
from sklearn.metrics import mean_squared_error
print("平均二乗誤差(トレーニングデータ): ", mean_squared_error(y_train, y_train))
print("平均二乗誤差(テストデータ): ", mean_squared_error(y_test, y_prediction))
# 平均二乗誤差(訓練データ): 0.0
# 平均二乗誤差(テストデータ): 33.42617425477851訓練データでモデルを作っているため、訓練データのMSEは必ず0になります。
さて、このままだとこのモデルが良いのか悪いのかが分かりませんので、例えば変数を全て入れて作成したモデルのMSEはどうなるかをみてみます。
#説明変数
X = df.iloc[:,:-1].values
#目的変数
y = df['MEDV'].values
#訓練データとテストデータの準備
from sklearn.model_selection import train_test_split
#既存のデータをトレーニングデータとテストデータに分割
# パラメータ:test_sizeでテストに使うデータの割合を指定可能
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
#linear_modelをimport
import sklearn.linear_model
#予測モデルの初期化
classifier2 = sklearn.linear_model.LinearRegression()
#Xを入力した時にyを出力するように学習
classifier2.fit(X_train, y_train)
#モデル評価
y_prediction = classifier2.predict(X_test)
print("平均二乗誤差(トレーニングデータ): ", mean_squared_error(y_train, y_train))
print("平均二乗誤差(テストデータ): ", mean_squared_error(y_test, y_prediction))
# 平均二乗誤差(トレーニングデータ): 0.0
# 平均二乗誤差(テストデータ): 27.195965766883234結果として全ての変数を使って予測モデルを構築した方が、私がピックアップした変数で学習するよりも良い結果が出ることが分かりました。ただし、前段で記載したように全ての説明変数を使うことで必ず予測精度が上がるかは限らないということと、説明変数が多くなれば多くなるほど処理時間が長くなってしまうということは覚えておいていただければと思います。
予測結果の可視化
モデルの評価は上記までで実施しましたので、今回は予測結果を可視化してみたいと思います。
まず最初に私が説明変数をピックアップして作成したモデルで線を引いてみます。
#予測結果の格納
y_pred = classifier.predict(X)
#グラフの描画
fig, ax = plt.subplots()
ax.scatter(y, y_pred, edgecolors=(0, 0, 0))
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
ax.set_xlabel('Measureed')
ax.set_ylabel('Predicted')
plt.show()
黒い点線が予測値、青く散らばっている丸が実際のデータです。
このようにグラフで可視化することで、予測値と実際のデータとの乖離を直感的に把握することが可能です。
次に全ての変数を入れたモデルでもグラフを描いてみます。
#予測結果の格納
y_pred2 = classifier2.predict(X)
#グラフの描画
fig, ax = plt.subplots()
ax.scatter(y, y_pred2, edgecolors=(0, 0, 0))
ax.plot([y.min(), y.max()], [y.min(), y.max()], 'k--', lw=4)
ax.set_xlabel('Measureed')
ax.set_ylabel('Predicted')
plt.show()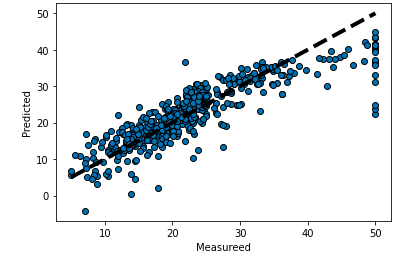
確かにこちらの方がなんとなくではありますが、当てはまりの良い回帰式になっているように見えることを確認できます。
以上が機械学習の基本的な流れです。いかがでしょうか。現実には機械学習にあたっては考慮すべき事項が多々ありますが、Pythonであれば思ったよりシンプルに機械学習できてしまうということを実感できたのではないでしょうか。
参考資料
この記事はUdemyの現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイルという講座と【データサイエンス×ビジネスコミュニケーション】現役データサイエンティストが教える「伝えて動かすデータ分析」という2つの講座を参考にさせていただき、作成しました。
現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
当講座はPythonの基礎から応用まで幅広く学べる講座なのでおすすめです。
この講座の講師はとにかくPythonについての知識が豊富ですし、話も適度な速さで聞き取りやすいです。さすがのシリコンバレーです。
また、最後の方に機械学習で使うライブラリについても解説があるので、データサイエンス・AIについても多少知ることができます。
当講座のおすすめポイントを以下にまとめておきます。
シリコンバレーで働いているということもあり、講師のPythonの知識が豊富
話も適度な速さで聞き取りやすい
コードの意味だけでなく、それをどう応用するかまで解説してくれる
【データサイエンス×ビジネスコミュニケーション】現役データサイエンティストが教える「伝えて動かすデータ分析」
当講座のおすすめポイントを以下にまとめておきます。
Pythonを知らなくても講座の中で学ぶことが可能なので初学者でもOK
データサイエンスの手法だけでなく、それをどのようにビジネスに活かすかまで学べる
この講座の最大の特徴は、データサイエンスを実務でどのように活かすかまで言及されている点です。
他の講座だとデー分析の手法や機械学習の実装方法だけ伝えるものもあるのですが、この講座はデータサイエンスの習得を目的とせず、その先を見据えた講義になっているので、実務での使用イメージが湧きやすいです。
なお、Udemyについては以下の記事でまとめていますのでご参考ください。

まとめ
ということで、今回はデータ分析でよく用いられるライブラリであるscikit-learnについて確認しました。
あやめデータと同様、ある程度Pythonを書くことができれば意外とデータ分析ができてしまうことを実感できるかと思います。
ただし、今回の構築したモデルはかなり精度が低いものでしたので、この先精度を上げるために地道にデータの選定し直しとモデルのチューニングが必要です。そして、これらを実施するためにはある程度の統計や機械学習の知識が必要となりますので、やはり自己学習を通じて色々な手法を学んでいくことが肝要かと思います。
では、今回はここまでとさせていただきます。