【データ分析】scikit-learnを使ってあやめデータを分析・機械学習してみる

こんにちは、爽です。皆さん、いかがお過ごしでしょうか?
今回はデータ分析でよく用いられるライブラリであるscikit-learnについて確認します。
scikit-learnは機械学習用のライブラリで、このライブラリを使えば多くの機械学習のアルゴリズムを自分で実装しなくても利用できる為、非常に便利です。今回はこのscikit-learnに同梱されているあやめのデータを使って基礎分析と機械学習をしてみます。
なお、こちらの記事はnumpy,pandas,matplotlibを理解できている前提で記載しています。
もし上記ライブラリの基本を知りたい方は以下の記事にまとめているので合わせてご参考ください。
・numpy
・pandas

・matplotlib

■この記事の対象読者
・データ分析に興味のある方
なお、私はPythonをAnacondaをインストールしてJupyterで実行しています。MacのAnacondaのインストール方法とJupyterの使い方は下記記事にまとめているので良かったらご参考ください。

それではどうぞ!
scikit-learnとは
scikit-learnとは冒頭に記載した通り、機械学習用のライブラリで当該ライブラリには複雑な機外学習のアルゴリズムがいくつも同梱されています。読み方は「サイキットラーン」です。
その為、統計学や機械学習に深い知見がなくとも、このライブラリを使えばとりあえず機械学習のアルゴリズムを簡単に実装できる為、非常に便利です。
なお、scikit-learnの中でも特に有名なのがこのチートシートです。
外部リンク:https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html
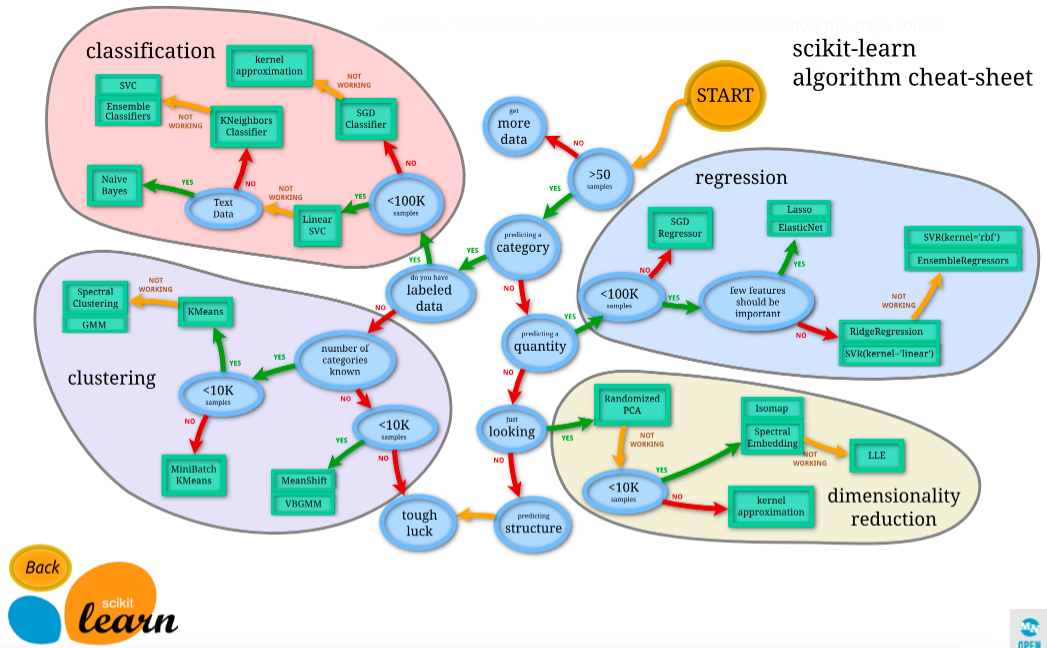
機械学習のアルゴリズムは非常にたくさん存在するので、どの分析でどのアルゴリズムを使用するか悩ましいところですが、このチートシートを使えば、分析の内容に合致したアルゴリズムを選択することが可能です。
チートシートは下記4つに分類されています。
classification(分類・教師あり学習)く
clustering(クラスタリング・教師なし学習)
regression(回帰・教師あり学習)
dimensionality reduction(次元削減/次元圧縮))
それぞれの詳細な内容は今回は割愛しますが、アルゴリズムの種類の豊富さとチートシートがあることから、scikit-learnは初学者から上級者まで幅広く用いられているライブラリです。
あやめデータの基礎分析
では早速、あやめデータの基礎分析をしてみたいと思います。あやめデータとは3種類のあやめのデータが入っているデータで、scikit-learnに事前にデータセットとして同梱されています。従って、scikit-learnさえ使える環境であれば、データを自分で準備する必要はありません。
ということでいろいろ分析をやっていきたいと思います。
まず分析の前に scikit-learnをインストールしていない人はpip installで入れてください。こんな感じに表示されればインストール完了です。
pip install sklearn
# Collecting sklearn
# Using cached sklearn-0.0-py2.py3-none-any.whl
# Requirement already satisfied: scikit-learn in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from sklearn) (1.0.2)
# Requirement already satisfied: numpy>=1.14.6 in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from scikit-learn->sklearn) (1.21.2)
# Requirement already satisfied: scipy>=1.1.0 in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from scikit-learn->sklearn) (1.7.3)
# Requirement already satisfied: joblib>=0.11 in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from scikit-learn->sklearn) (1.1.0)
# Requirement already satisfied: threadpoolctl>=2.0.0 in /Users/ユーザー名/opt/anaconda3/lib/python3.9/site-packages (from scikit-learn->sklearn) (2.2.0)
# Installing collected packages: sklearn
# Successfully installed sklearn-0.0
# Note: you may need to restart the kernel to use updated packages.
データ読み込み
まずはデータを読み込みます。
#データ読み込み
from sklearn.datasets import load_iris
iris = load_iris()なお、このままだと配列の形式でデータが取得されるのでみやすいようにpandasを使って、データフレームに変換します。
#データフレームとして表示
import pandas as pd
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
df
target以外は説明変数でtarget以外は目的変数です。targetが本当に3種類なのかをunique()関数で確認します。
df['target'].unique()
# array([0, 1, 2]) #targetは確かに3種類データ品質確認
データを読み込めたらいきなり分析をするのではなく、読み込んだデータの品質を確認することが分析の鉄則です。
例えば欠損値、外れ値などの不正な値が存在するままに分析を進めてしまうと後続の機械学習で良い結果を出すことが出来ないためです。とりあえず欠損値、外れ値の確認と基礎統計を取りたい場合はdescribe()メソッドが便利です。
df.describe()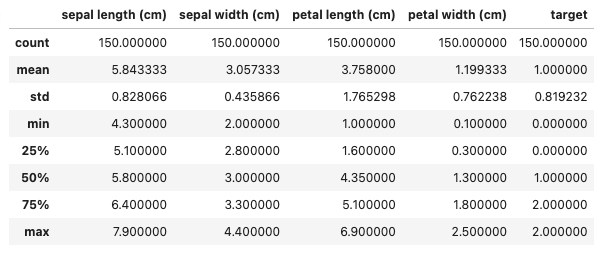
結果を見るとどの列にもデータの欠損はなく、ぱっと見大きな外れ値もないため、データ品質としては問題ないものとして分析を進めて良いかと思います。
集計
データを読み込めたところで、データを集計してtargetごとの特徴を掴みます。
describe()メソッドでは全体の特徴は掴めますが、targetごとに特徴を掴むためにはgroupby()を使用します。
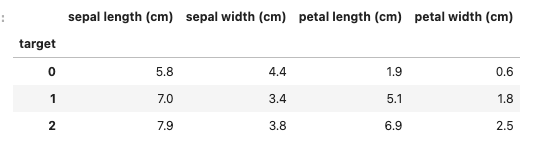
#平均
df.groupby('target').mean()
#最大
df.groupby('target').max()
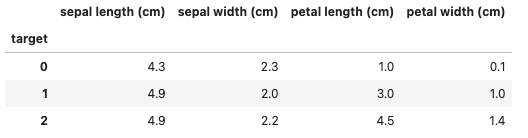
#最小
df.groupby('target').min()
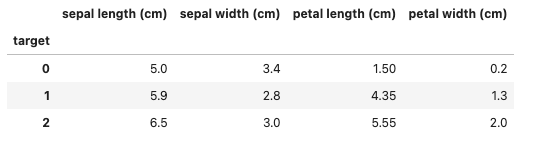
#中央値
df.groupby('target').median()
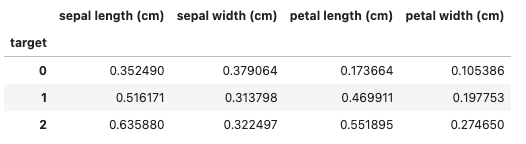
#標準偏差
df.groupby('target').std()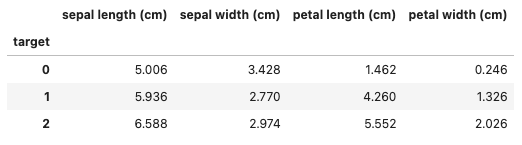
データの可視化
上記のように集計してみてみると何となく傾向は把握できますが、直感的に素早く理解するためにはグラフを使うことも重要です。
#seabornのインストール
#pip install seaborn
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#色を指定
color_map = ['b', 'r', 'g']
for target, target_name in enumerate(iris.target_names):
target_iris_df = df[df.target == target]
plt.scatter(
target_iris_df['sepal length (cm)'],
target_iris_df['sepal width (cm)'],
label=target_name,
c=color_map[target])
plt.legend()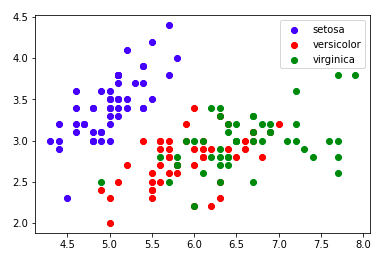
for target, target_name in enumerate(iris.target_names):
target_iris_df = df[df.target == target]
plt.scatter(
target_iris_df['petal length (cm)'],
target_iris_df['petal width (cm)'],
label=target_name,
c=color_map[target])
plt.legend()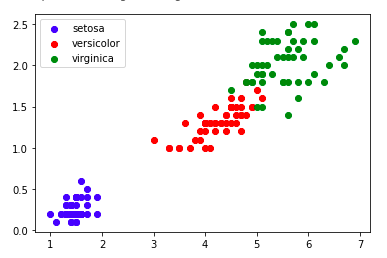
この2枚のグラフから読み取れることは、setosaという品種は1番小さく、その次にversicolorという品種が小さく、virginicaという品種が最も大きいということです。
このように統計量をグラフで可視化すると各targetの特徴が明確になり、その後の分析とモデルの構築・およびモデルの評価といった流れがスムーズに進められます。
あやめデータで機械学習
さて、データについての理解が深まったところでいよいよ機械学習をやってみます。
今回のデータでやりたいことは、ある説明変数を入力したときにtargetがどの品種に分類されるかを予測することです。従って、今回はSVM(サポートベクターマシン)のアルゴリズムを使用した教師あり学習の分類をやってみます。
訓練データとテストデータの準備
機械学習するためには、訓練データを用いてモデルを学習させる必要があります。
ただし、全てのデータを使って学習してしまうと、そのモデルの評価ができないため、テスト用のデータも準備する必要があります。訓練データとテストデータの分け方については様々な手法がありますが、ここでは最もシンプルな交差検証(クロスバリデーション)と呼ばれる最もシンプルな手法を用います。
#必要なライブラリの読み込み
import pandas as pd
import numpy as np
#データの用意(あやめデータ)
from sklearn.datasets import load_iris
iris = load_iris()
#説明変数
X_raw = iris.data
#目的変数
y = iris.target
#差が顕著であったpetal length (cm)とpetal width (cm)を抜き出し、説明変数として用いる
X = X_raw[:, [2,3]] # 3, 4列目を抽出
#訓練データとテストデータの準備
from sklearn.model_selection import train_test_split
#既存のデータをトレーニングデータとテストデータに分割
#パラメータ:test_sizeでテストに使うデータの割合を指定可能
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
#fデータの確認
print("X: ", X.shape)
print("X_train: %s / X_test: %s / y_train: %s / y_test: %s" % (X_train.shape, X_test.shape, y_train.shape, y_test.shape))
# X: (150, 2)
# X_train: (105, 2) / X_test: (45, 2) / y_train: (105,) / y_test: (45,)29行目、30行目の結果を見てみると、訓練データ、テストデータの説明変数、目的変数ともに指定の割合で分割されていることが分かります。
ここで分割したX_trainとy_trainを使ってモデルを構築します。
モデル構築
上記で訓練データを用意できたため、このデータを用いてモデルを構築していきます。
モデルの構築もscikit-learnを使えば非常にシンプルに実装できます。
#サポートベクターマシンをimport
from sklearn import svm
#予測モデル(分類器=classifier)の初期化
classifier = svm.SVC()
#Xを入力した時にyを出力するように学習
classifier.fit(X_train, y_train)例えば今回の例でいくとわずか3行でモデルの構築ができてしまいました。
基本は必要なアルゴリズムをimport→モデルの初期化→fitで学習の手順で進めます。
さて、学習が終わったらpredict()メソッドを使って、テストデータを用いることで結果の予測が可能です。
#作成した予測モデルでテストデータの予測
y_pred = classifier.predict(X_test)
y_pred
# array([2, 1, 0, 2, 0, 2, 0, 1, 1, 1, 2, 1, 1, 1, 1, 0, 1, 1, 0, 0, 2, 1,
# 0, 0, 1, 0, 0, 1, 1, 0, 2, 1, 0, 2, 2, 1, 0, 2, 1, 1, 2, 0, 2, 0,
# 0])評価
さて、機械学習の最後に構築したモデルがどの程度優れているものなのかを評価する必要があります。
評価の手法も様々なものがありますが、今回は「正解率」を用いてモデルの評価を行います。「正解率」とは言葉通りですが、テストデータのうち、いくつ正しく分類することが出来たかの割合を持ってモデルを評価することです。従って、この割合が高ければ高いほど優れたモデルであるということが出来ます。
#モデルの評価
from sklearn.metrics import accuracy_score
print("正解率: ", accuracy_score(y_test, y_pred))
# 正解率: 0.9777777777777777今回のモデルの「正解率」は97%ほどなので非常に精度の高いモデルを構築できたと言えそうです。
以上が機械学習の基本的な流れです。いかがでしょうか。現実には機械学習にあたっては考慮すべき事項が多々ありますが、Pythonであれば思ったよりシンプルに機械学習できてしまうということを実感できたのではないでしょうか。
参考資料
この記事はUdemyの【データサイエンス×ビジネスコミュニケーション】現役データサイエンティストが教える「伝えて動かすデータ分析」という講座を参考にさせていただき、作成しました。
【データサイエンス×ビジネスコミュニケーション】現役データサイエンティストが教える「伝えて動かすデータ分析」
当講座のおすすめポイントを以下にまとめておきます。
Pythonを知らなくても講座の中で学ぶことが可能なので初学者でもOK
データサイエンスの手法だけでなく、それをどのようにビジネスに活かすかまで学べる
この講座の最大の特徴は、データサイエンスを実務でどのように活かすかまで言及されている点です。
他の講座だとデー分析の手法や機械学習の実装方法だけ伝えるものもあるのですが、この講座はデータサイエンスの習得を目的とせず、その先を見据えた講義になっているので、実務での使用イメージが湧きやすいです。
なお、Udemyについては以下の記事でまとめていますのでご参考ください。

まとめ
ということで、今回はデータ分析でよく用いられるライブラリであるscikit-learnについて確認しました。
numpy,pandas,matplotlibとscikit-learnを少し使うことができれば、意外と簡単な分析と機械学習ならばできてしまうということを実感できたかと思います。
ただし、この記事で紹介していることは本当に基礎的な部分となり、現実にはこれだけの知識だけでは太刀打ちできませんので自己学習を通じて色々な手法を学んでいくことが肝要かと思います。
このブログでもデータサイエンス系の話題をもっと深ぼっていけたらと思っています。
では、今回はここまでとさせていただきます。