【データ分析】MovieLensを使って映画をクラスタリングで分類してみる

こんにちは、爽です。皆さん、いかがお過ごしでしょうか?
今回は映画のレビューデータであるMovie Lensを使って、教師なし学習の一つであるクラスタリングをやってみたいと思います。クラスタリングは教師あり学習とは異なり、正解のデータがない中で大量データをいくつかの類似のグループに分類する手法で、実業務では顧客のセグメンテーションやターゲティングなどに用いられます。
なお、今回の記事はnumpy,pandas,matplotlibを理解できている前提で記載しています。
もし上記ライブラリの基本を知りたい方は以下の記事にまとめているので合わせてご参考ください。
・numpy
・pandas

・matplotlib

■この記事の対象読者
・データ分析に興味のある方
なお、私はPythonをAnacondaをインストールしてJupyterで実行しています。MacのAnacondaのインストール方法とJupyterの使い方は下記記事にまとめているので良かったらご参考ください。

それではどうぞ!
クラスタリングとは
クラスタリングとは冒頭に記載したように、正解のデータがない中で大量データをいくつかの類似のグループに分類する手法です。イメージとしては以下の左図のようにプロットされた複数のデータを右図のようにいくつかのグループに分けものと考えると分かりやすいかもしれません。



クラスタリングを使いこなすことができれば、大量のデータの特徴を機械が学習することで、短時間でグルーピングできる為、顧客のセグメンテーションやターゲティングを効率的に実現することが可能です。
データの読み込み
今回はMovieLensという映画情報とユーザーによるレビュー情報が入っているデータとなります。本来は推薦システムの開発やベンチマークのために作られたデータセットであるようですが、このように分析の題材にも用いられます。今回は読み込んだ映画をいくつかにグルーピングしていくことを目的としていきます。
では早速データを読み込んでいきたいと思います。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#データセットの読み込み
url = 'http://files.grouplens.org/datasets/movielens/ml-100k/u.item'
#区切り文字の指定とヘッダーの有無と文字コードの指定
df = pd.read_csv(url, sep='|', header=None, encoding='latin-1')
df.head()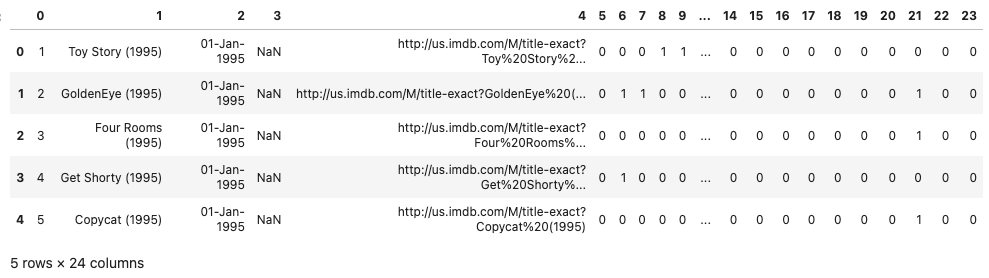
このデータは列名がないので、列名を付与します。
#列情報の追加
#ホームページから取得 http://files.grouplens.org/datasets/movielens/ml-100k-README.txt
col = "id | movie title | release date | video release date | IMDb URL | unknown | Action | Adventure | Animation | Children's | Comedy | Crime | Documentary | Drama | Fantasy | Film-Noir | Horror | Musical | Mystery | Romance | Sci-Fi | Thriller | War | Western"
col_names = col.split(" | ")
#列名を追加
df.columns = col_names
df.head()各列の意味は以下となります。
- movie id:映画のID
- movie title:映画のタイトル
- release date :リリース日
- video release date:ビデオのリリース日
- IMDb URL:データセットの元となるURL(アクセスすると情報が見れる)
- 6列目以降:映画のジャンル情報(19列分あり、その映画が該当のジャンルの場合は1が振られ、そうでない場合は0となる)
今回は6列目以降の映画のジャンル情報を用いて、映画をいくつかのグループに分類してみたいと思います。
従って、6列目以降を説明変数として取り出し、以降はこのデータを学習データとして用います。
#ジャンル情報列のみ抽出してこれを学習データとして用いる
X = df.iloc[:, 5:]
X
映画データをクラスタリング
ここまででデータを用意できたのでここからクラスタリングのモデルを構築していきます。今回はk-means(k-平均法)というクラスタリングの代表的なアルゴリズムを使用します。
と、モデルを構築するその前に今回クラスタリングを実施する中で直面する一つの問題として挙げられるのが、映画を果たしていくつのグループに分類するのが適切かを判断することだと思います。その問題の解決策として挙げられるのがエルボー法と呼ばれる手法です。
エルボー法
エルボー法とはWCSS(Within Cluster Sum of Squares)が大きく減ったところのクラスターの数を採用するというものです。WCSSとはある点から各データまでの距離の総和のことで、この数字はクラスターの数が増えるほど減るという反比例の関係にあります。つまりこのWCSSとクラスターの関係を見て適切なクラスターの数を見るのがエルボー法です。
、、文章で書くと分かりづらいため、matplotlibを使ってグラフを描画してみます。
from sklearn.cluster import KMeans
wcss = []
for i in range(1, 11):
#iのクラスター数に応じて、k平均法でモデルを構築する
kmeans = KMeans(n_clusters = i, init = 'k-means++', random_state = 42)
kmeans.fit(X)
#inertia_は厳密にはwcssではないとのことだが、ほぼ同義と見做して問題ないとのこと
wcss.append(kmeans.inertia_)
plt.plot(range(1, 11), wcss)
plt.title('The Elbow Method')
plt.xlabel('Number of clusters')
plt.ylabel('WCSS')
plt.show()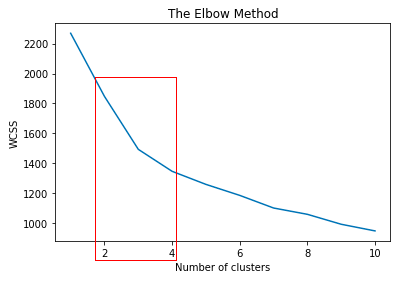
matplotlibで描いたグラフを見ると、赤枠で示したクラスター数2〜3の間が最もWCSSの減少幅が大きく、次点でクラスター数3〜4の減少幅が大きいです。そして、クラスター数が増えていくにつれてWCSSの減少幅は減っています。従って、今回の例で言うと2〜4の間で分類するのが良さそうと判断することが出来ます。
本来であればクラスターの数を色々調整して結果を比較するのが良いですが、今回はクラスター数を4で進めたいと思います。
ちなみにエルボー法とはグラフが肘のように見えることから命名されていると思われます。
モデルの構築
モデルの構築はscikit-learnできます。scikit-learnは本当に便利ですね!
kmeans = KMeans(n_clusters=4, random_state=42).fit(X)しかも1行。かなりお手軽ですね。
結果の可視化と考察
さて、モデルの構築ができたので最後のステップとして、k-meansによってどのようにクラスタリングされたか可視化し、その結果について考察してみたいと思います。
結果の可視化
まず元のデータに今回の予測結果をマージします。
df['cluster_label'] = kmeans.labels_
df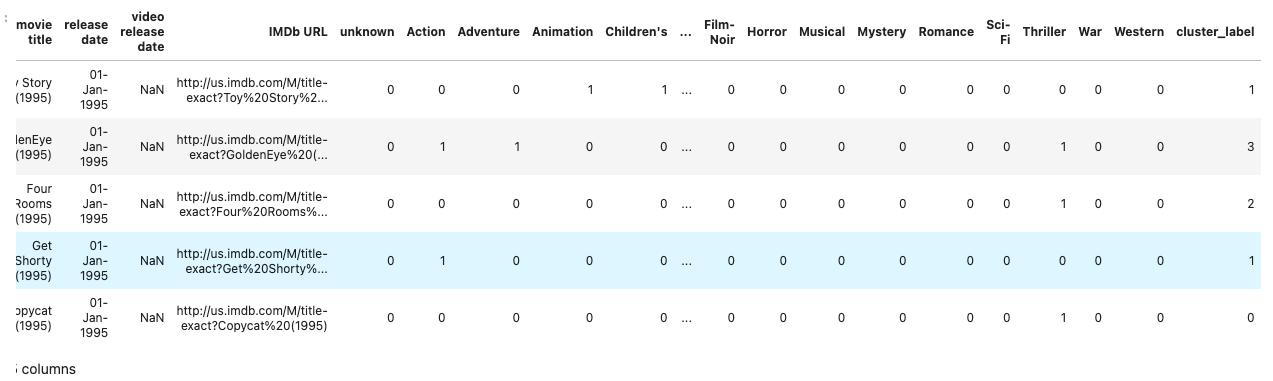
1番右の列にラベル付けをすることが出来ました。次にどれがどのくらいどのクラスタに分類されたかを確認します。
label_size = df['cluster_label'].value_counts().sort_index()
print(label_size)
print(label_size / label_size.sum())
# 0 622
# 1 492
# 2 365
# 3 203
# Name: cluster_label, dtype: int64
# 0 0.369798
# 1 0.292509
# 2 0.217004
# 3 0.120690
# Name: cluster_label, dtype: float64次に各クラスタにどのジャンルがそれぞれどれくらいの割合で含まれているかを可視化してみます。
cluster_genre_df = df[col_names[5:] + ['cluster_label']].groupby('cluster_label').sum().T
cluster_genre_ratio_df = (cluster_genre_df / cluster_genre_df.sum())
cluster_genre_ratio_df.head()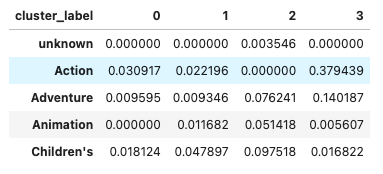
さらに直感的にわかりやすく把握するためにseabornのヒートマップで可視化してみます。
sns.heatmap(cluster_genre_ratio_df, cmap='Blues')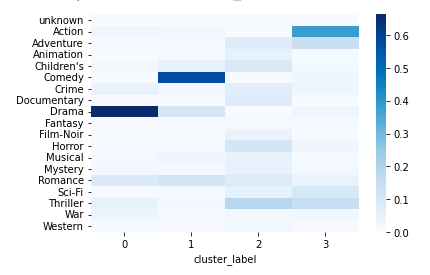
結果の考察
上記のヒートマップの結果から各クラスタは以下のような解釈ができると思います。
クラスタ0:Dramaが6割以上占めており、他にRomanceとCrimeが入っていることから大人向けのジャンルのカテゴリとして分類された可能性がある
クラスタ1:Comedyが5割ほど占めていることから、お笑い系のジャンルのカテゴリとして分類された可能性がある
クラスタ2:あまり特徴がないがThriller、Horrorがあることから、少し暗いジャンルのカテゴリとして分類された可能性がある
クラスタ3:Action、Thrillerが多くを占めることから、アクション系のカテゴリとして分類された可能性がある
ここに挙げた解釈方法はあくまで例で、人によって様々な解釈ができるところでありますので、ヒートマップと各クラスタの中身を見ることで、当事者間で共通認識を持テルレベルまで各クラスタへの理解を深めることが大事だと考えています。
参考資料
この記事はUdemyの【データサイエンス×ビジネスコミュニケーション】現役データサイエンティストが教える「伝えて動かすデータ分析」と【世界で74万人が受講】基礎から理解し、Pythonで実装!機械学習26のアルゴリズムを理論と実践を通じてマスターしよういう講座の2つを参考にさせていただき、作成しました。
【データサイエンス×ビジネスコミュニケーション】現役データサイエンティストが教える「伝えて動かすデータ分析」
当講座のおすすめポイントを以下にまとめておきます。
Pythonを知らなくても講座の中で学ぶことが可能なので初学者でもOK
データサイエンスの手法だけでなく、それをどのようにビジネスに活かすかまで学べる
この講座の最大の特徴は、データサイエンスを実務でどのように活かすかまで言及されている点です。
他の講座だとデー分析の手法や機械学習の実装方法だけ伝えるものもあるのですが、この講座はデータサイエンスの習得を目的とせず、その先を見据えた講義になっているので、実務での使用イメージが湧きやすいです。
【世界で74万人が受講】基礎から理解し、Pythonで実装!機械学習26のアルゴリズムを理論と実践を通じてマスターしよう

当講座のおすすめポイントを以下にまとめておきます。
機械学習のアルゴリズムを直感的な解説と実践を通じて学べる
複雑なアルゴリズムの内容を数式中心ではなく、図を用いて説明してくれるので数学の知識がなくてもOK
機械学習だけでなく、ディープラーニング、強化学習にも言及されている
この講座はタイトルの通り、機械学習のアルゴリズムを理論と実践を通じて学ぶことができるものです。なお、理論といっても、この講座では複雑な数式はなるべく図を多く用いて説明してくれているので、数学の知識がなくても理解ができる内容なので、データサイエンス初学者でも問題なく学習を進められます。また、機械学習だけでなく、ディープラーニングや強化学習にも言及されていることから、データサイエンス領域を広く学んでみたい方にもおすすめです。
なお、Udemyについては以下の記事でまとめていますのでご参考ください。

まとめ
ということで、今回は映画のレビューデータであるMovie Lensを使って、教師なし学習の一つであるクラスタリングをやってみました。
記事で書いた通り、クラスタリングのモデル構築は簡単に出来ますが、今回のように1700程度のデータをもし人手で分類しようとするとそれこそ数時間はかかってしまうことを、一瞬で分類できてしまうので非常に有用な手法であるということを実感いただけたのではないでしょうか。そして、これを実務にも応用できると業務の効率化も期待できそうであることは言うまでもありませんので、使える場面があればどんどん使っていきたいですね。
では、今回はここまでとさせていただきます。